
رگرسیون لجستیک: درک مبانی و کاربردها
دسترسی سریع
در حوزه تحلیل داده و مدلسازی پیشبینی، رگرسیون لجستیک (Logistic Regression) بهعنوان ابزار قدرتمند و گسترده محسوب میشود. توانایی آن در مقابله با مسائل دستهبندی دودویی و ارائه بینشهای ارزشمند درباره احتمال روی دادن یک رویداد، آن را به ابزار ضروری برای پژوهشگران، تحلیلگران و دانشمندان داده تبدیل کرده است.
بینظر از اینکه در زمینه تحقیقات پزشکی، تجزیه و تحلیل بازاریابی یا پیشبینی مالی فعالیت دارید، رگرسیون لجستیک یک ابزار چندمنظوره است که میتواند به شما در درک و پیشبینی نتایج کمک کند. با بررسی ارتباط بین متغیرهای مستقل متعدد و یک نتیجه دودویی، این مدل به شما اجازه میدهد تا احتمال وقوع یک رویداد را تخمین بزنید.
در این مقاله، به بررسی مبانی رگرسیون لجستیک میپردازیم، انواع و کاربردهای آن را توضیح میدهیم. همچنین آن را با ماشین لرنینگ و رگرسیون خطی مقایسه میکنیم.
مفهوم رگرسیون لجستیک
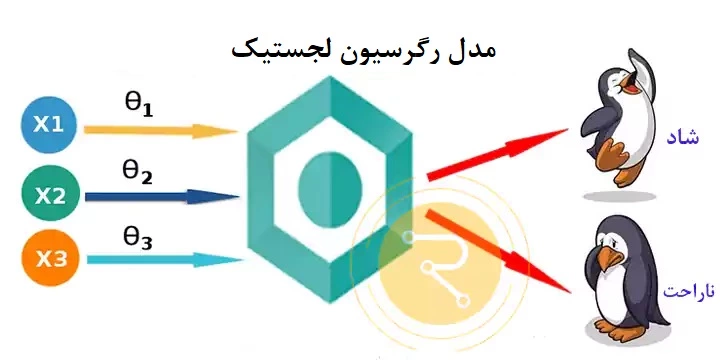
رگرسیون لجستیک (Logistic Regression) یک الگوریتم یادگیری ماشین نظارت شده است که عمدتا برای وظایف طبقهبندی (classification) استفاده میشود و هدف آن پیشبینی احتمال تعلق یک نمونه به یک کلاس مشخص است.
در واقع، رگرسیون لجستیک یک تابع خطی را بهعنوان ورودی میگیرد و مقادیر آن را از طریق تابع سیگموئید (sigmoid function) به بازهای محدود بین ۰ و ۱ تبدیل میکند. این مقادیر تفسیر شده و بهعنوان احتمال تعلق به یک کلاس خاص تلقی میشوند. برای مثال، اگر احتمال تعلق یک نمونه به یک کلاس برابر با ۰.۸ باشد، بهاین معنی است که احتمال اینکه نمونه در آن کلاس قرار داشته باشد، بسیار بالاست.
رگرسیون خطی در مقابل رگرسیون لجستیک
هر دو رگرسیون خطی و لجستیک مدلهای محبوب در علم داده هستند و ابزارهای متنباز مانند Python و R ، محاسبات مربوط به آنها را سریع و آسان میکنند.
>>>> مدلهای رگرسیون خطی برای شناسایی رابطه بین یک متغیر وابسته پیوسته و یک یا چند متغیر مستقل استفاده میشوند. وقتی تنها یک متغیر مستقل و یک متغیر وابسته وجود داشته باشد، به آن رگرسیون خطی ساده گفته میشود، اما با افزایش تعداد متغیرهای مستقل، به رگرسیون خطی چندگانه اشاره میشود.
>>>> مشابه رگرسیون خطی، رگرسیون لجستیک نیز برای تخمین ارتباط بین یک متغیر وابسته و یک یا چند متغیر مستقل استفاده میشود، اما برای پیشبینی، متغیر طبقهای (Categorical Variable) در مقایسه با یک متغیر پیوسته به کار میرود. یک متغیر طبقهای میتواند درست یا غلط، بله یا خیر، 1 یا 0 و غیره باشد.
>>>> واحد اندازهگیری نیز در رگرسیون خطی با Logistic Regression متفاوت است. در رگرسیون خطی، واحد اندازهگیری نتیجه پیشبینی معمولا پیوسته است، مانند مقادیر عددی. اما در رگرسیون لجستیک، نتیجه پیشبینی بهصورت احتمالی است و بین ۰ و ۱ قرار میگیرد. اما تابع لوجیت در رگرسیون لجستیک این منحنی احتمال را به خط راست تبدیل میکند، بهاین ترتیب نتیجه پیشبینی بهصورت خطی قابل نمایش میشود.
>>>> با اینکه هر دو مدل در تحلیل رگرسیون برای پیشبینی نتایج آینده استفاده میشوند، رگرسیون خطی به طور عمومی قابل فهمتر است. همچنین نیاز به اندازه نمونه کمتری دارد، در حالی که رگرسیون لجستیک برای نمایش مقادیر در تمام دستههای پاسخ نیاز به نمونهای مناسب دارد. بدون نمونه بزرگ و نماینده، ممکن است مدل قدرت آماری کافی برای تشخیص تأثیر معنیدار را نداشته باشد.
انواع رگرسیون لجستیک
3 نوع مدل رگرسیون لجستیک وجود دارد که براساس پاسخ طبقهای تعریف میشوند.
رگرسیون لجستیک دودویی (Binary logistic regression)
در این روش، متغیر پاسخ یا وابسته ماهیت دوگانه دارد، بهاین معنی که تنها دو نتیجه ممکن برای آن وجود دارد (مانند ۰ و ۱). برخی مثالهای معروف استفاده از این روش شامل پیشبینی اینکه یک ایمیل اسپم است یا نه، یا اینکه یک تومور بدخیم است یا نه، هستند.
در رگرسیون لجستیک، این روش بیشترین استفاده را دارد و به طور کلی، یکی از رایجترین ردهبندها برای طبقهبندی باینری است.
مثالی از رگرسیون لجستیک باینری
فرض کنید یک مجموعه داده داریم که شامل اطلاعاتی درباره دانشآموزان است، مانند نمرات آزمون (X) و وضعیت پذیرش (Y) که میتواند دو مقدار 0 (پذیرفته نشده) و 1 (پذیرفته شده) را داشته باشد. میخواهیم مدل رگرسیون لجستیک باینری بسازیم تا با توجه به نمرات آزمون، احتمال پذیرش را پیشبینی کنیم.
با استفاده از این مجموعه داده، میتوانیم یک مدل رگرسیون لجستیک را با سازگاری آن با دادهها آموزش دهیم. مدل رابطه بین نمرات امتحانی و احتمال پذیرش را یاد خواهد گرفت. هنگامی که مدل آموزش دیده باشد، میتوانیم از آن برای پیشبینی احتمال پذیرش برای دانشآموزان جدید بر اساس نمرات امتحانی آنها استفاده کنیم.
برای نمونه، فرض کنید یک دانشآموز جدید با نمره آزمون 80 داریم. میتوانیم این نمره را به عنوان ورودی به مدل رگرسیون لجستیک آموزشدیده بدهیم و این مدل احتمال پذیرش را خروجی خواهد داد. اگر احتمال پیشبینی شده بالاتر از یک آستانه خاص (مانند 0.5) باشد، میتوانیم دانشآموز را به عنوان "پذیرفته شده" (1) دستهبندی کنیم و اگر کمتر از آستانه باشد، دانشآموز را به عنوان "پذیرفته نشده" (0) دستهبندی کنیم.
بهاین ترتیب، رگرسیون لجستیک دودویی به ما کمک میکند تا پیشبینیها را انجام داده و نمونههای جدید را براساس رابطه بین متغیرهای ورودی (نمرات آزمون) و نتیجه دودویی (وضعیت پذیرش) به یکی از دو دسته تقسیم کنیم.
رگرسیون لجستیک ترتیبی (Ordinal logistic regression)
این نوع مدل در مواردی که متغیر پاسخ بیش از 3 نتیجه ممکن داشته باشد (برخلاف رگرسیون لجستیک دودویی که فقط دو دسته دارد)، مورد استفاده قرار میگیرد. با این حال، در این نوع مدل، مقادیر ممکن برای متغیر پاسخ دارای یک ترتیب معین هستند، بهاین معنی که دستهها با یک ترتیب خاص قرار دارند و این ترتیب در تحلیل و تفسیر نتایج مدل بسیار مهم است.
مثلاً در مقیاس نمره A تا F، دسته A بهترین و دسته F بدترین نمره را نشان میدهد و در مقیاس امتیازدهی 1 تا 5، امتیاز 5 بهترین و امتیاز 1 بدترین امتیاز است. در این نوع رگرسیون، هدف پیشبینی احتمال وقوع هر یک از دستههای متغیر پاسخ بر اساس متغیرهای ورودی است.
رگرسیون لجستیک چندجملهای (Multinomial logistic regression)
در این نوع مدل رگرسیون لجستیک، متغیر وابسته سه یا بیشتر نتیجه ممکن دارد؛ با این حال، این مقادیر ترتیب مشخصی ندارند. به عنوان مثال، استودیوهای سینمایی میخواهند پیشبینی کنند که یک بیننده سینما احتمالا چه ژانری از فیلم را تماشا خواهد کرد تا فیلمها را به طرز مؤثرتری بازاریابی کنند.
مدل رگرسیون لجستیک چندجملهای به استودیو کمک میکند تا قدرت تأثیر سن، جنسیت و وضعیت رابطه عاطفی یک فرد بر روی نوع فیلمی که او ترجیح میدهد را تعیین کند. سپس استودیو میتواند یک کمپین تبلیغاتی خاص برای یک فیلم خاص را به یک گروه افرادی که احتمالاً تماشای آن را دارند، هدایت کند.
یک مدل رگرسیون لجستیک چندجملهای به استودیو کمک میکند تا قدرت تأثیر سن، جنسیت و وضعیت ازدواج یک شخص را بر روی نوع فیلمی که ترجیح میدهد، تعیین کند. سپس استودیو میتواند یک کمپین تبلیغاتی خاص برای یک فیلم به گروهی از افراد که احتمال دیدن آن را دارند، هدایت کند.
در این روش، رگرسیون لجستیک چندجملهای به ما کمک میکند تا پیشبینیها را انجام داده و نمونهها را براساس تأثیر متغیرهای ورودی (مانند سن، جنسیت و وضعیت ازدواج) بر روی نتایج چندجملهای (ژانر فیلم) دستهبندی کنیم.
رگرسیون لجستیک و یادگیری ماشین
در دنیای یادگیری ماشین، رگرسیون لجستیک به خانواده مدلهای یادگیری ماشین نظارتشده تعلق دارد. این مدل به عنوان یک مدل تمییزدهنده شناخته میشود، به این معنا که سعی در تمییز دادن بین کلاسها یا دستهها دارد. برخلاف الگوریتمهای تولیدی مانند بیز ساده (naïve bayes)، رگرسیون لجستیک نمیتواند اطلاعاتی را تولید کند و تصویری از دستهای که قصد پیشبینی آن را دارد (مانند تصویر یک گربه) تولید نماید.
بیشینه کردن تابع درستنمایی
در اینجا، ما به توضیح میپردازیم که چگونه رگرسیون لجستیک برای تعیین ضرایب بتا مدل، تابع درستنمایی بر اساس لگاریتم را بیشینه میکند. این مسئله در زمینه یادگیری ماشین تغییرات کوچکی میکند. در یادگیری ماشین، ما از تابع منفی لگاریتم درستنمایی به عنوان تابع اشتباه (loss function) استفاده میکنیم و با استفاده از فرآیند کاهش گرادیان، به دنبال یافتن مقدار بیشینه کلی میگردیم.
قبلا اشاره کردیم که چگونه رگرسیون لجستیک برای تعیین ضرایب بتا مدل، تابع درستنمایی برحسب لگاریتم (log likelihood function) را بیشینه میکند. این مسئله در زمینه یادگیری ماشین تغییرات کوچکی میکند. در یادگیری ماشین، ما از تابع منفی لگاریتم درستنمایی به عنوان تابع اشتباه (loss function) استفاده میکنیم و با استفاده از فرآیند کاهش گرادیان، به دنبال یافتن مقدار بیشینه کلی (global maximum) میگردیم.
کنترل بیشبرازش
رگرسیون لجستیک ممکن است در مواجهه با تعداد زیادی متغیر پیشبین درون مدل، به بیشبرازش (overfitting) حساس باشد. برای مقابله با بیشبرازش، از روش منظمسازی (regularization) استفاده میشود که در آن، ضرایب پارامترها (یا وزنها) با استفاده از جریمهدهی مجازی کاهش مییابند. این جریمهدهی به ضرایب بزرگ، منجر به کاهش اهمیت آنها میشود و مدل را به سمت یافتن توزیع متوازنتری از پارامترهای کوچکتر هدایت میکند. این روش به مدل کمک میکند تا در مقابل بیشبرازش مقاومت بیشتری داشته باشد و عملکرد بهتری روی دادههای جدید ارائه دهد.
موارد استفاده از رگرسیون لجستیک
رگرسیون لجستیک به طور رایج برای مسائل پیشبینی و طبقهبندی استفاده میشود. برخی از این موارد استفاده عبارتند از:
تشخیص تقلب
این مدلها به تیمها کمک میکنند تا ناهنجاریهای داده را که پیشبینی کننده تقلب هستند، شناسایی کنند. برخی از رفتارها یا ویژگیها ممکن است با فعالیتهای تقلبی ارتباط بیشتری داشته باشند و با استفاده از رگرسیون لجستیک، میتوان این ارتباط را مدلسازی و تشخیص دادههای تقلبی را بهبود بخشید. این بخش بهویژه برای بانکها و مؤسسات مالی در حفاظت از مشتریان بسیار مفید است. همچنین، شرکتهای مبتنی بر نرمافزار نیز از این روشها استفاده کردهاند تا هنگام انجام تحلیل داده درباره عملکرد کسبوکار، حساب کاربریهای جعلی را از مجموعه دادههای خود حذف کنند و تحلیلهای دقیقتری را ارائه دهند.
پیشبینی بیماری
در زمینه پزشکی و بهداشت، استفاده از تجزیه و تحلیل داده برای پیشبینی احتمال بروز بیماریها یا ناهنجاریهای بهداشتی بسیار حیاتی است. با تحلیل دادههای مربوط به یک جمعیت، میتوان افرادی را که احتمال بیشتری برای بیماریهای خاصی دارند، شناسایی کرده و برنامههای مراقبت پیشگیرانه برای آنها تدوین کرد. این کار به سازمانهای بهداشتی و ارائه دهندگان مراقبتهای بهداشتی امکان میدهد تا منابع خود را به بهترین شکل ممکن تخصیص دهند و بر اساس اطلاعات دقیقتر به افراد مشاوره و درمان مناسب را ارائه دهند.
پیشبینی ترک کردن
رفتارهای خاص ممکن است نمایانگر ترککردن (یا از دست دادن) در اقسام مختلف یک سازمان باشند. بهعنوان مثال، تیمهای منابع انسانی و مدیریت ممکن است بخواهند بدانند آیا افراد با عملکرد بالا در شرکت هستند که در معرض خطر ترک کردن سازمان هستند؛ این نوع اطلاعات میتواند به برگزاری گفتوگوها برای درک نقاط ضعف در داخل شرکت، مانند فرهنگ یا حقوق و دستمزد، منجر شود.
در مقابل، تیم فروش ممکن است بخواهد بفهمد کدام یک از مشتریانشان در معرض خطر انتقال کسب و کار به جای دیگری هستند. این میتواند تیمها را به تدوین استراتژی نگهداشت (Retention) مشتریان بیپایان ترغیب کند تا از از دست دادن درآمد جلوگیری کنند.
این اطلاعات ارزشمند به سازمانها کمک میکند تا منابع و استراتژیهای مناسبی را تخصیص دهند و از از دست دادن ارزشها جلوگیری کنند.
خلاصه کلام
رگرسیون لجستیک یک ابزار قدرتمند در دستهبندی دادهها و پیشبینی احتمالات مربوط به کلاسهای مختلف است و در علوم داده و یادگیری ماشینی از اهمیت بسیاری برخوردار است.
چه در زمینه رگرسیون لجستیک تازه کار باشید و چه بهدنبال تعمیق درک خود هستید، این مقاله بهعنوان راهنمای جامع عمل میکند و شما را به دانش و مهارت هایی مجهز می کند تا رگرسیون لجستیک را بهطور موثر در پروژه های تجزیه و تحلیل دادههای خود بهکار ببرید.
نظرات
هیچ نظری وجود ندارد.
افزودن نظر
مشاهده نقشه سایت
Copyright © 2017 - 2023 Khavarzadeh®. All rights reserved